What is a Data Pipeline? Definitions You Need to Know
What is a data pipeline? Learn about the terminology used when discussing a data pipeline, including definitions related to DataOps.

Editor’s Note: Given the continued evolution of IT automation, we thought it timely to refresh our 2021 point of view on data pipelines.
The data pipeline is filled with a cornucopia of legacy and emerging terms, but if you’re new to the subject, don’t fret — it becomes simple once you understand the core concepts. This article aims to define and break down some of the most relevant keywords, phrases, and difficult terms.
Data Pipeline Defined
A data pipeline follows a workflow of stages or actions, often automated, that move and combine data from various sources to prepare data insights for end-user consumption.
The stages within an end-to-end pipeline consist of:
- Collection of disparate raw source data
- Integration and ingestion of data
- Storage of data
- Computation and analysis of data
- Delivery of insights to the business via methods that include analytics, dashboards, or reports
Without a thorough data pipeline, it’s easy for data to be misused, lost, damaged, or neglected.
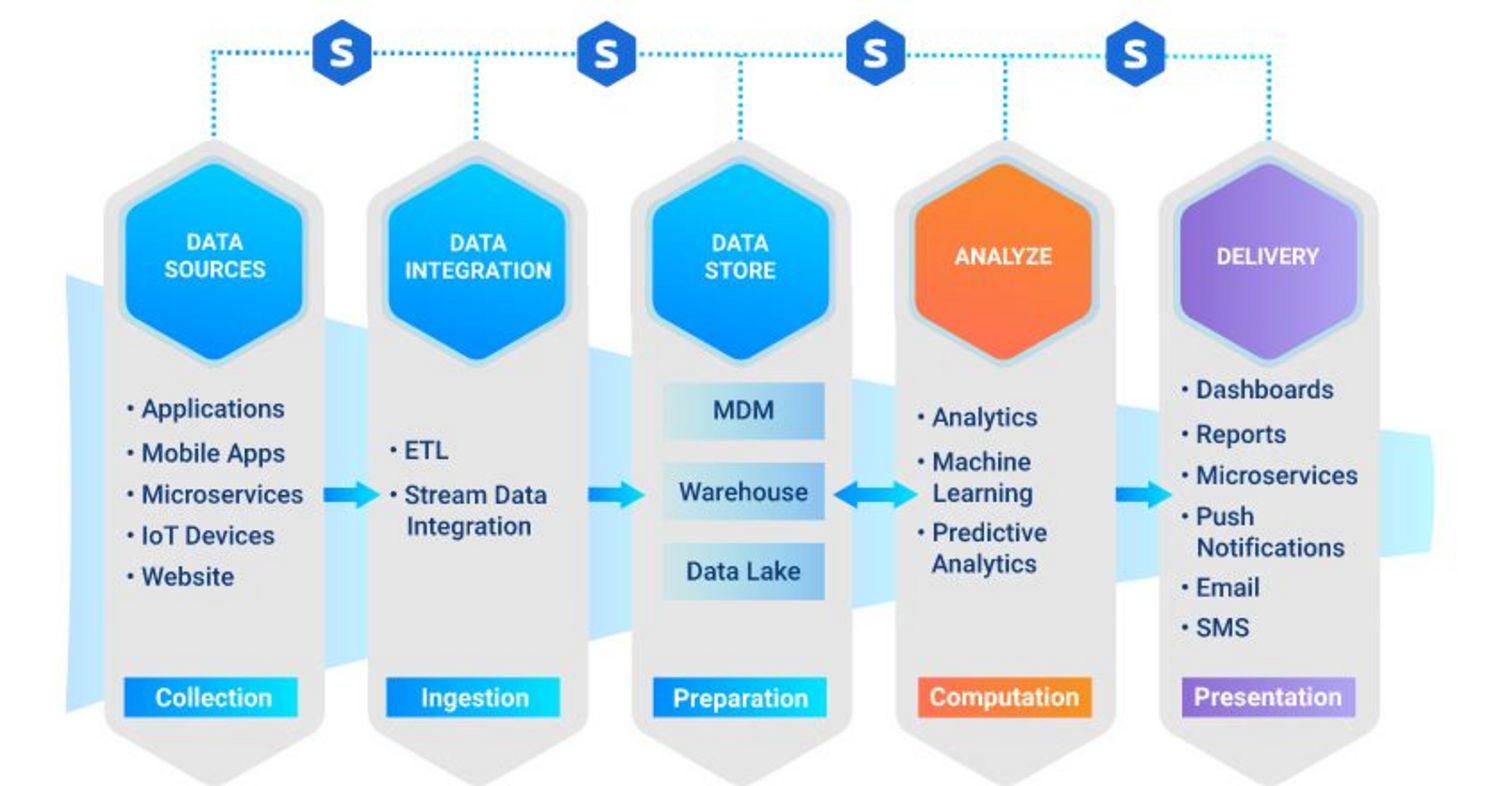
Stages within a Data Pipeline
As with any pipeline, the data pipeline moves through a number of key stages. Each stage is integral to achieving the desired result; that is, gaining as much value from your data as possible.
The five key stages are:
- Data source. This is the data created within a source system, which includes applications or platforms. Within a data pipeline, there are multiple source systems. Each source system has a data source in the form of a database or data stream.
- Data integration and ingestion. Data integration is the process of combining data from different sources into a single, unified view. Integration begins with the ingestion process; it includes steps such as cleansing, ETL mapping, and transformation. Data is extracted from the sources, then consolidated into a single, cohesive data set.
- Data storage. This stage represents the "place" where the cohesive data set lives. Data lakes and data warehouses are two common solutions to store big data, but they are not equivalent technologies:
- A data lake is typically used to store raw data, the purpose for which is not yet defined.
- A data warehouse is used to store data that has already been structured and filtered for a specific use.
(A good way to remember the difference is to think of the data lake as a place where all the rivers and streams pour into without being filtered.)
- Analysis and Computation. This is where analytics, data science, and machine learning happen. Tools that support data analysis and computation pull raw data from the data lake or data warehouse. New models and insights (from both structured data and streams) are then stored in the data warehouse.
- Delivery. Finally, insights from the data are shared with the business. The insights are delivered through dashboards, emails, SMSs, push notifications, and microservices. The machine learning model inferences are exposed as microservices.
Additional Terminology and Solution Types
To fully understand the data pipeline purpose and process, there are several other key terms to become familiar with.
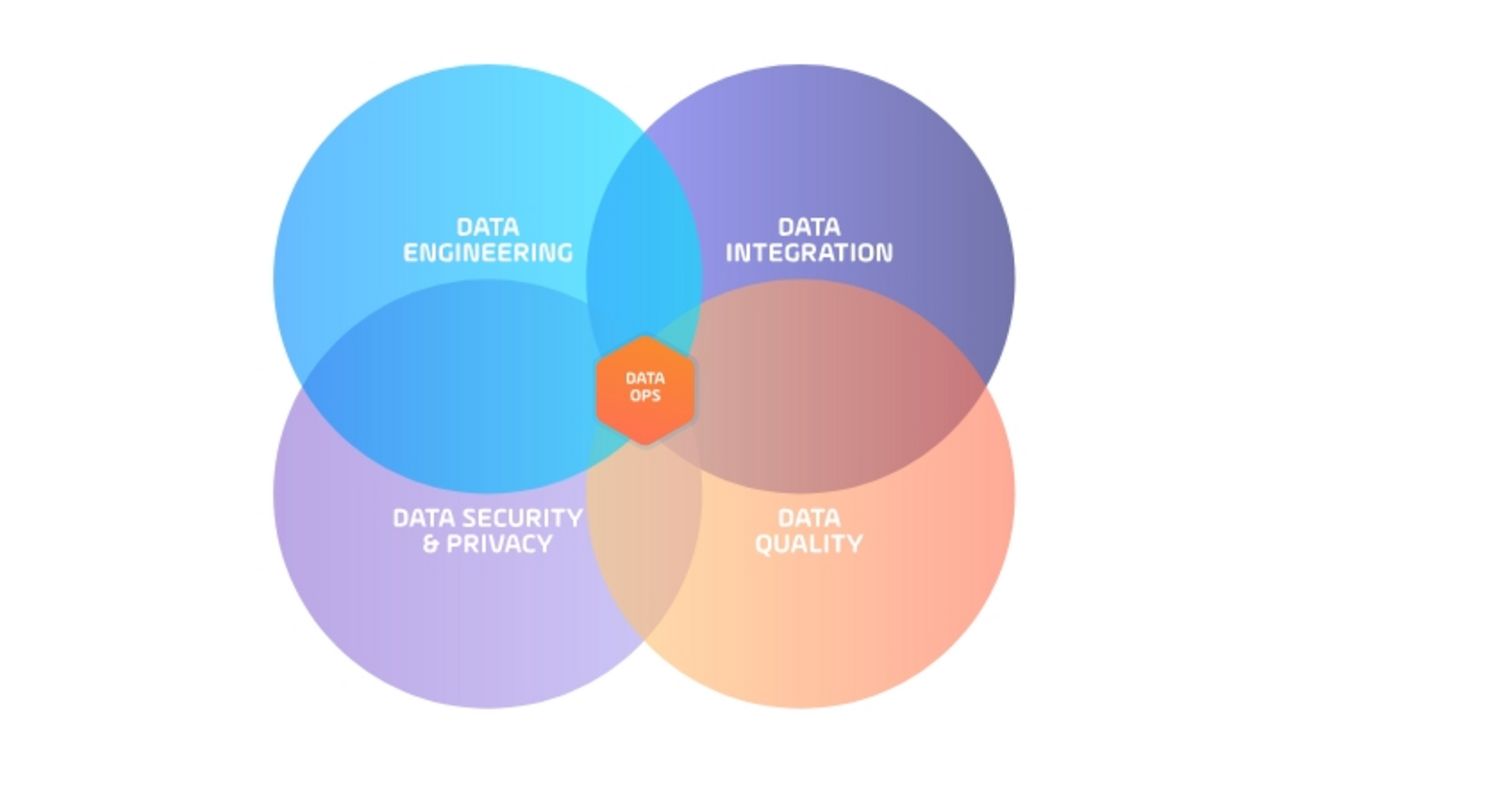
DataOps (data operations) is an emerging discipline that provides the tools, processes, and organizational structures to support an automated, process-oriented methodology used by analytic and data teams.
Typically, DataOps teams are created by applying DevOps methodologies to a centralized team made up of data engineers, integration, security, data quality, and data scientist roles. The aim? To improve the overall quality and to reduce the cycle time of data analytics.
Streaming Data represents data that is generated all the time by many data sources. Sources often range in the thousands, all of which send data records simultaneously in small (kilobyte) sizes.
Extract, Transform, Load (ETL) is a type of data integration approach used to ingest data from multiple sources. Data is first extracted from its source or sources. That data is then transformed according to business logic. Finally, data is typically loaded into a data warehouse.
Extract, Load, Transform (ELT) is an alternative approach to ETL (above) used with a data lake implementation, where data does not necessarily need to be transformed before storage. Instead, the raw data is pushed into the data lake, which produces faster loading times.
DataOps Enabled is the technology that allows data teams to manage a data pipeline with a DevOps-like approach to support pipelines-as-code. This approach uses standard lifecycle methodologies (dev/test/prod) that include versioning and simulated tests for end-to-end orchestration.

Data Pipeline Orchestration is a solution that DataOps teams use to centralize the management and control of end-to-end data pipelines. Data teams integrate the orchestration solution to each data tool they use along the data pipeline, after which the data pipeline orchestration solution automates the data tool’s actions. This helps to move data through each stage of the entire pipeline reliably.
The benefits of an orchestration approach often include monitoring and reporting, proactive alerts, DataOps enablement, and the real-time movement of data with event-based system triggers.
Service Orchestration and Automation Platform (SOAP). As a category coined by Gartner in April 2020, SOAPs evolved from traditional workload automation solutions. Today, SOAPs help I&O teams to provide automation-as-a-service to the business.
One primary solution built within SOAPs is data pipeline orchestration. SOAPs are ideal platforms to orchestrate the data pipeline because of their graphical workflow designer, ability to integrate with any third-party tools, and built-in managed file transfer capabilities.
SOAPs became prominent because of the popularity of the cloud, which led to organizations needing automation to be orchestrated across both on-prem and cloud environments.
Summary
The data pipeline is complex; there’s no way to remove its intricacies, or else it would be rendered significantly less effective. However, orchestrating and automating the flow of data through a data pipeline is an entirely obtainable objective.
With the definitions above, you’re one step closer to figuring out how to adapt your data pipeline strategy. This article summarizes the big picture view of why enterprises are focused on automating the data pipeline; it’s an excellent next step if you are further intrigued by the subject.
Start Your Automation Initiative Now
Schedule a Live Demo with a Stonebranch Solution Expert




