Un pipeline de données, qu’est-ce que c’est ? Les définitions à connaître absolument
Un pipeline de données, qu’est-ce que c’est ? Découvrez la terminologie utilisée dans les discussions sur les pipelines de données, y compris les définitions touchant aux DataOps.

Note de la rédaction : Compte tenu de l’évolution constante de l’automatisation informatique, nous avons pensé qu’il était judicieux de revoir notre analyse de 2021 concernant les pipelines de données.
Le thème des pipelines de données est associé à une profusion de termes anciens et nouveaux. Si vous êtes novice en la matière, ne vous affolez pas : il vous suffit de comprendre les concepts de bases, et tout devient simple. Cet article vise à définir et à expliquer certains des principaux mots-clés, expressions et termes.
Définition des pipelines de données
Un pipeline de données suit une série d’étapes ou d’actions, souvent automatisées, qui déplacent et combinent les données provenant de diverses sources afin de les préparer pour les mettre à la disposition des utilisateurs finals.
Les étapes d’un pipeline complet sont les suivantes :
- Collecte de données brutes hétérogènes
- Intégration et ingestion des données
- Stockage des données
- Calcul et analyse des données
- Mise à disposition des résultats par le biais de supports divers tels qu’analyses, tableaux de bord ou rapports.
Sans un pipeline de données rigoureux, il est facile d’utiliser les données à mauvais escient, de les perdre, de les endommager ou de ne pas les prendre en compte.
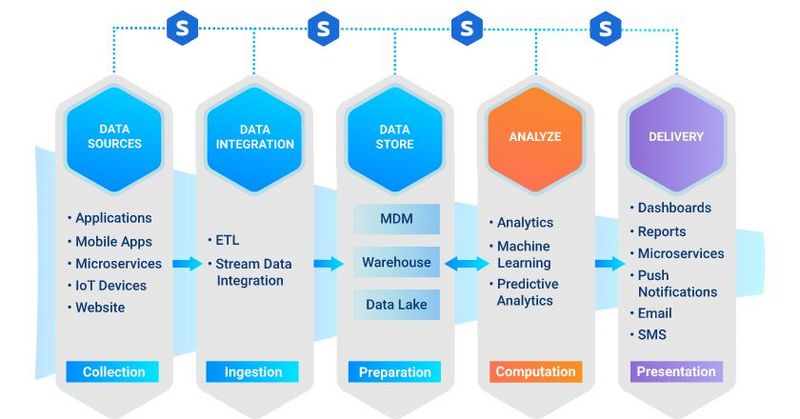
Les étapes du pipeline de données
Comme tout pipeline, le pipeline de données dispose d’un certain nombre d’étapes clés. Chacune de ces étapes est indispensable pour atteindre le résultat souhaité, c’est-à-dire tirer le maximum de valeur des données.
Les cinq étapes principales sont :
- La source des données. Les données sont générées dans un système source composé d’applications et de plateformes. Il y a de nombreux systèmes sources dans un pipeline de données et chacun d’entre eux dispose d’une source de données sous la forme d’une base ou d’un flux de données.
- L’intégration et l’ingestion des données. L’intégration des données est le processus qui consiste à combiner des données provenant de différentes sources en une vue unifiée. L’intégration commence par la phase d’ingestion qui comprend des activités telles que le nettoyage, le mappage ETL et la transformation. Les données sont extraites des sources, puis consolidées en un seul ensemble homogène.
- Le stockage des données. Cette étape représente le « domicile » où réside l’ensemble de données cohérent. Les lacs et les entrepôts de données sont deux solutions courantes pour stocker les importants volumes de données, mais il ne s’agit pas de technologies équivalentes :
- Un lac de données est normalement utilisé pour stocker des données brutes dont la finalité n’est pas encore définie.
- Un entrepôt de données sert quant à lui à stocker des données qui ont déjà été structurées et filtrées pour un usage déterminé.
(Un moyen de se souvenir de la différence est de se représenter le lac de données comme un endroit où les rivières et les ruisseaux se déversent sans être filtrés).
- Les analyses et les calculs. C’est l’étape où interviennent les analyses, la science des données et l’apprentissage automatique. Les outils qui prennent en charge les analyses et les calculs des données extraient des données brutes du lac ou de l’entrepôt de données. Les nouveaux modèles et les résultats des analyses (provenant à la fois des données structurées et des flux) sont ensuite stockés dans l’entrepôt.
- La mise à disposition. Finalement, les résultats des analyses sont mis à la disposition de l’entreprise par le biais de tableaux de bord, de mails, de SMS, de notifications push et de micro-services. Les conclusions du modèle d’apprentissage automatique sont présentées sous forme de micro-services.
Terminologie complémentaire et types de solutions
Afin de bien comprendre la finalité et le processus d’un pipeline de données, il faut se familiariser avec plusieurs autres termes clés.
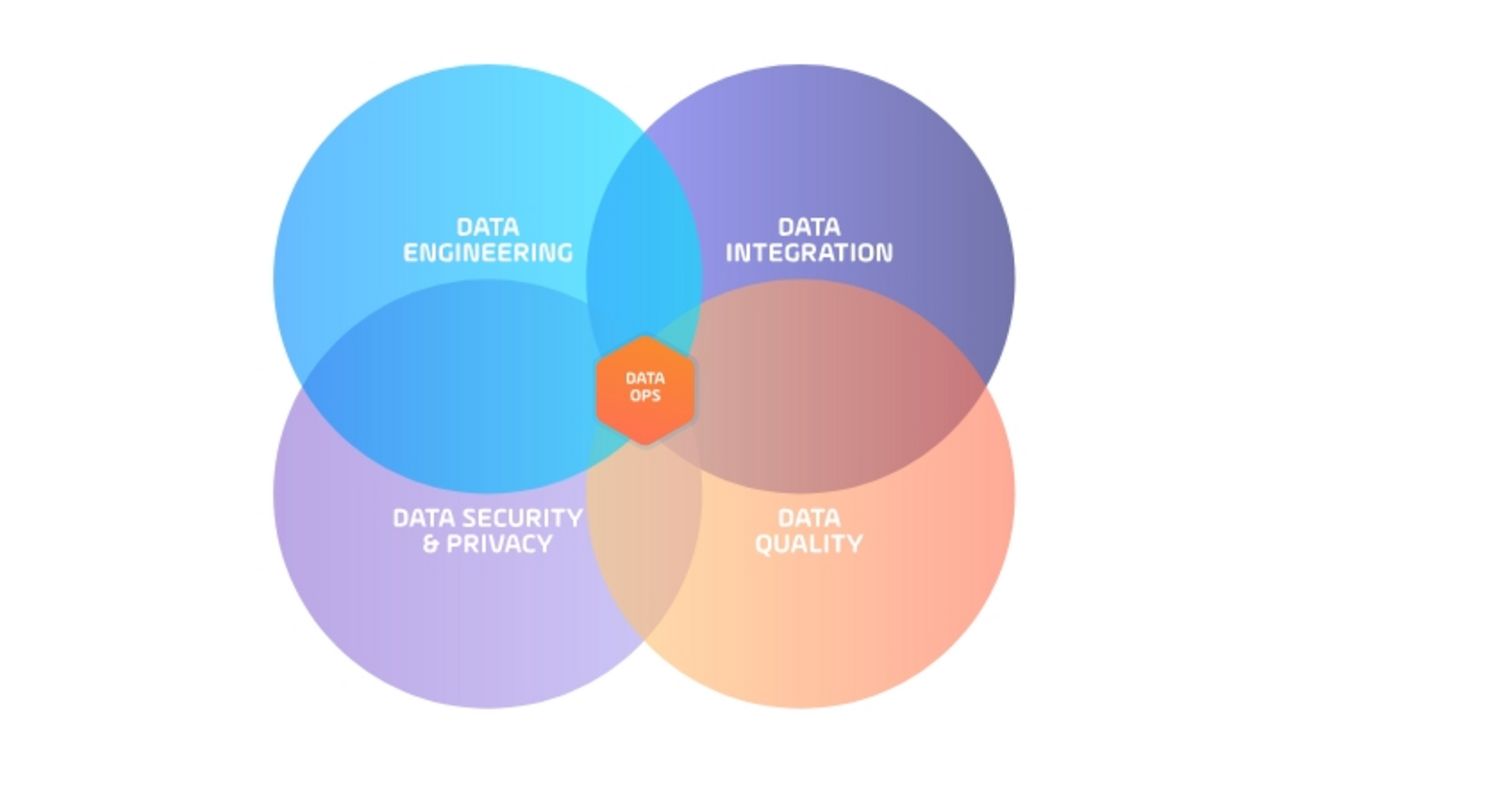
DataOps (data operations) est une discipline émergente qui fournit les outils, les processus et les structures organisationnelles pour mettre en œuvre une méthodologie automatisée et orientée processus utilisée par les équipes d’analytique et de données.
En règle générale, les équipes DataOps sont créées en appliquant des méthodologies DevOps à une équipe centralisée composée d’ingénieurs de données, de spécialistes de l'intégration, de la sécurité, de la qualité des données ainsi que d’experts en sciences des données. Avec quel objectif ? Améliorer la qualité générale et réduire la durée du cycle d’analyse des données.
Les données en continu (streaming data) sont les données générées en continu par diverses sources qui se comptent souvent par milliers et envoient simultanément des jeux de données de petite taille (quelques ko).
Extract, Transform, Load (ETL) est une approche d’intégration utilisée pour ingérer des données issues de sources multiples. Les données sont tout d’abord extraites de sa ou de ses sources. Puis elles sont transformées en fonction de l’utilisation prévue. Et finalement, elles sont généralement placées dans un entrepôt de données.
Extract, Load, Transform (ELT) est une alternative à l’approche ETL (voir ci-dessus). Elle est utilisée pour l’implémentation dans un lac de données, ces dernières ne devant pas obligatoirement être transformées avant leur stockage. Les données brutes sont simplement transférées dans le lac, ce qui permet des temps de chargements plus rapides.
DataOps Enabled est la technologie qui permet aux équipes chargées des données de gérer un pipeline avec une approche de type DevOps pour prendre en charge les pipelines en tant que code. Cette approche utilise des méthodologies de cycle de vie standard (dev/test/prod) qui incluent le versioning et des tests simulés pour une orchestration de bout en bout.

L’orchestration des pipelines de données est une solution mise en œuvre par les équipes DataOps pour centraliser la gestion et le contrôle des pipelines de données. Les équipes intègrent cette solution à chaque outil de données qu’elles utilisent tout au long du pipeline, après quoi la solution d’orchestration du pipeline de données automatise les activités de l’outil concerné. Ce qui permet d’acheminer les données de manière fiable à chaque étape du pipeline.
Parmi les avantages d’une approche d’orchestration, on citera notamment la surveillance et le reporting, les alertes proactives, le soutien de DataOps et le traitement des données en temps réel avec des déclencheurs basés sur les événements.
Plateformes d’orchestration et d’automatisation des services (SOAP). En tant que catégorie créée par Gartner en avril 2020, les SOAP ont évolué à partir des solutions traditionnelles d’automatisation des workloads. Aujourd’hui, les SOAP aident les équipes I&O à fournir des services d’automatisation à l’entreprise.
L’orchestration des pipelines de données est l’une des principales solutions intégrées aux SOAP. Grâce à leur concepteur graphique de flux de travail, la possibilité de les incorporer à des outils tiers et leurs fonctionnalités intégrées de transfert de fichiers géré, les SOAP sont les plateformes idéales pour l’orchestration des pipelines de données.
Les SOAP ont pris de l’importance avec la montée en puissance du cloud. Les entreprises ont en effet alors eu besoin d’une automatisation orchestrée à la fois dans leurs environnements sur site et dans les environnements cloud.
En résumé
Un pipeline de données est complexe ; il n’est pas possible d’en supprimer les finesses sans risquer de le rendre nettement moins efficace. Il est cependant tout à fait possible d’orchestrer et d’automatiser le flux d’informations passant par un pipeline de données.
Les définitions ci-dessus vous auront mis sur la bonne voie pour mieux être en mesure d’ajuster votre stratégie de pipeline de données. Cet article résume les raisons pour lesquelles les entreprises se concentrent sur l’automatisation du pipeline de données. Si vous souhaitez en savoir davantage sur le sujet, n’hésitez pas à le consulter.
Start Your Automation Initiative Now
Schedule a Live Demo with a Stonebranch Solution Expert




