Was ist eine Datenpipeline? Definitionen, die Sie kennen sollten
Was ist eine Datenpipeline? Lernen Sie die wichtigsten Begriffe rund um das Thema kennen, einschließlich Definitionen zu DataOps.

Anmerkung der Redaktion: Angesichts der fortschreitenden Entwicklung der IT-Automatisierung fanden wir es an der Zeit, unseren Artikel aus dem Jahr 2021 zum Thema Datenpipelines zu aktualisieren.
Das Thema Datenpipeline steckt voller alter und neuer Begriffe. Aber keine Sorge, falls Sie bisher noch keine Berührungspunkte damit hatten: Wenn Sie erst einmal die Kernkonzepte verstehen, wird alles viel einfacher. In diesem Artikel möchten wir einige der wichtigsten Schlüsselwörter, Ausdrücke und schwierigen Begriffe definieren und aufschlüsseln.
Datenpipelines – eine Definition
Eine Datenpipeline folgt einem Workflow aus Phasen oder Aktionen, oft automatisiert, die Daten aus verschiedenen Quellen verschieben und kombinieren, um Daten-Insights für Endbenutzer aufzubereiten.
Die Phasen innerhalb einer durchgehenden Pipeline sind:
- Erfassung von Rohdaten aus unterschiedlichen Quellen
- Integration und Aufnahme der Daten
- Speicherung der Daten
- Berechnung und Analyse der Daten
- Bereitstellung von Insights für das Unternehmen über verschiedene Methoden, darunter Analysen, Dashboards oder Berichte
Ohne eine solide Datenpipeline können Daten leicht missbraucht, verloren, beschädigt oder vernachlässigt werden.
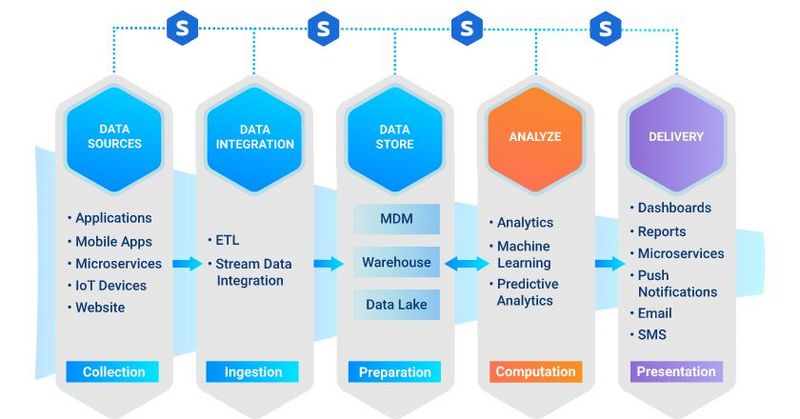
Phasen innerhalb einer Datenpipeline
Wie jede Pipeline durchläuft auch die Datenpipeline eine Reihe von Phasen, die wichtig sind, um das gewünschte Ergebnis zu erzielen, d. h. den größtmöglichen Nutzen aus Ihren Daten zu ziehen.
Das sind die fünf Schlüsselphasen:
- Datenquelle. Das sind die Daten, die in einem Quellsystem aus unterschiedlichen Anwendungen oder Plattformen erstellt werden. Innerhalb einer Datenpipeline gibt es mehrere Quellsysteme, von denen jedes eine Datenquelle in Form einer Datenbank oder eines Datenstroms hat.
- Datenintegration und -aufnahme. Datenintegration ist der Prozess, bei dem Daten aus verschiedenen Quellen in einer einzigen, vereinheitlichten Ansicht kombiniert werden. Die Integration beginnt mit dem Aufnahmeprozess (auch Daten Ingestion genannt), der Schritte wie Bereinigung, ETL-Mapping und Transformation umfasst. Die Daten werden aus den Quellen extrahiert und dann zu einem einzigen, zusammenhängenden Datensatz konsolidiert.
- Datenspeicherung. Diese Phase stellt den „Ort“ dar, an dem der zusammenhängende Datensatz aufbewahrt wird. Zwei gängige Lösungen zur Speicherung von Big Data sind Data Lakes und Data Warehouses, die sich allerdings in einigen Punkten unterscheiden:
- Ein Data Lake wird in der Regel zur Speicherung von Rohdaten verwendet, deren Zweck noch nicht definiert ist.
- In einem Data Warehouse dagegen werden Daten gespeichert, die bereits für eine bestimmte Verwendung strukturiert und gefiltert wurden.
(Ein guter Weg, sich den Unterschied zu merken, ist, sich den Data Lake wie einen See vorzustellen, in den alle Datenflüsse und -ströme ungefiltert zusammenkommen).
- Analyse und Berechnung. In dieser Phase finden Analytik, Data Science und maschinelles Lernen statt. Tools, die die Datenanalyse und -berechnung unterstützen, ziehen Rohdaten aus dem Data Lake oder Data Warehouse. Neue Modelle und Erkenntnisse (sowohl aus strukturierten Daten als auch aus Datenströmen) werden dann im Data Warehouse gespeichert.
- Bereitstellung. Zu guter Letzt werden die Datenerkenntnisse an das Unternehmen weitergegeben, und zwar über Dashboards, E-Mails, SMS, Push-Benachrichtigungen und Microservices. Die Rückschlüsse aus den maschinellen Lernmodellen werden als Microservices bereitgestellt.
Zusätzliche Fachbegriffen und Lösungstypen
Um den Zweck der Datenpipeline und deren Ablauf voll und ganz zu verstehen, müssen Sie sich noch mit einigen anderen wichtigen Begriffen vertraut machen.
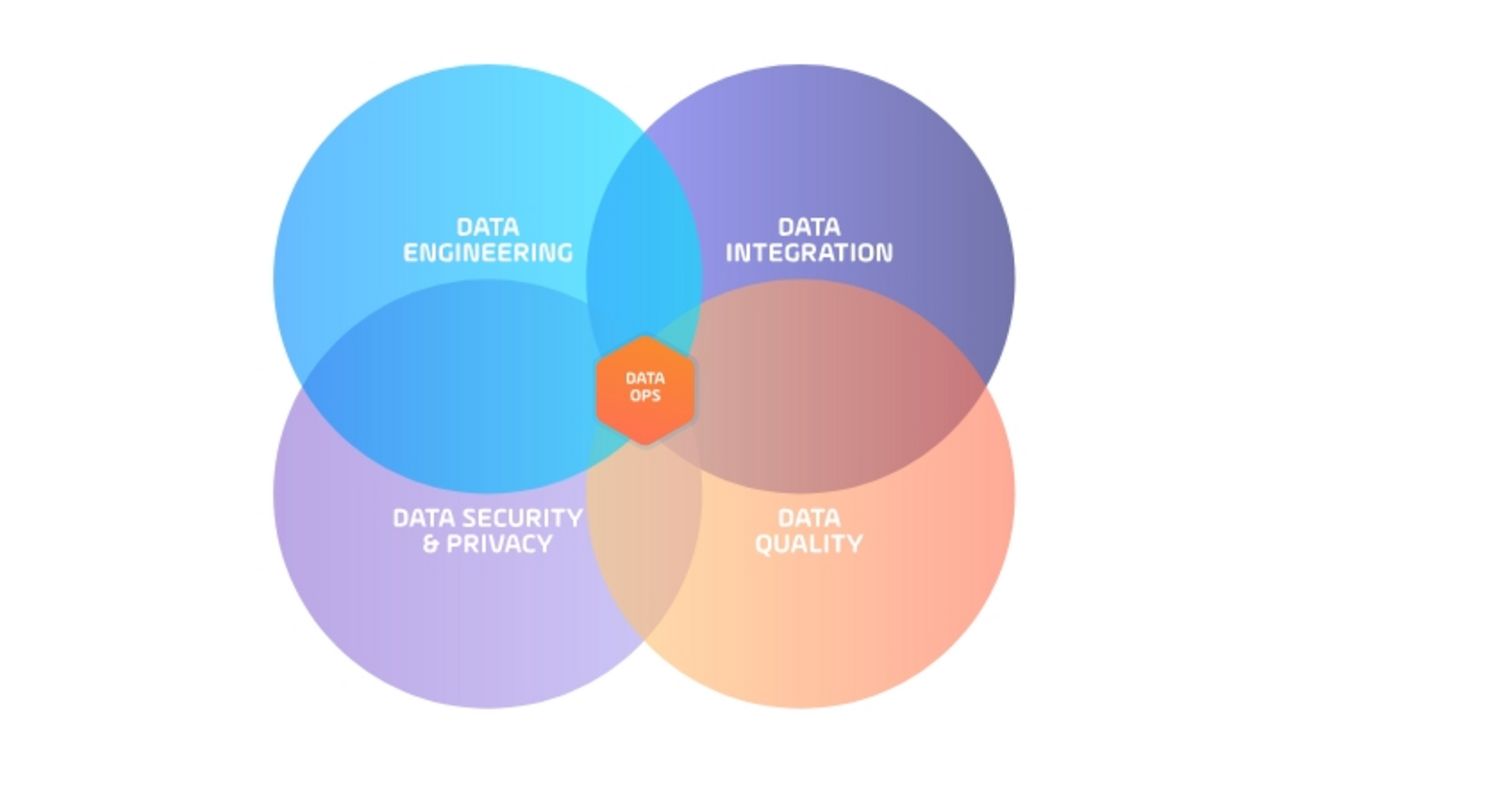
DataOps (Data Operations) ist eine noch junge Disziplin, die die Tools, Prozesse und Organisationsstrukturen zur Unterstützung einer automatisierten, prozessorientierten Methodik für Analyse- und Datenteams bereitstellt.
Um DataOps-Teams zu bilden, werden normalerweise DevOp-Methodologien auf ein zentralisiertes Team übertragen, das sich aus Dateningenieuren, Integrations-, Sicherheits-, Datenqualitäts- und Datenwissenschaftlern zusammensetzt. Ihr Ziel ist es, die Gesamtqualität zu optimieren und die Zykluszeit der Datenanalyse zu verkürzen.
Streaming Data bezeichnet Daten, die laufend von vielen Datenquellen erzeugt werden. Oft sind es Tausende von Quellen, die alle gleichzeitig Datensätze in kleinen Größen (Kilobyte) senden.
Extraktion, Transformation, Laden (ETL) ist eine Art Datenintegrationsansatz, der verwendet wird, um Daten aus mehreren Quellen aufzunehmen. Die Daten werden zunächst aus ihrer Quelle oder ihren Quellen extrahiert, dann entsprechend der Geschäftslogik transformiert und schließlich – in den meisten Fällen – in ein Data Warehouse geladen.
Extraktion, Laden, Transformation (ELT) ist ein Alternativverfahren zu ETL (siehe oben) und wird bei Data Lake-Implementierungen eingesetzt, bei der die Daten vor der Speicherung nicht unbedingt transformiert werden müssen. Stattdessen werden die Rohdaten in den Data Lake geschoben, was zu schnelleren Ladezeiten führt.
DataOps Enabled ist eine Technologie, mit der Datenteams eine Datenpipeline mit einem DevOps-ähnlichen Ansatz verwalten können, um Pipelines-as-Code zu unterstützen. Dieser Ansatz verwendet Standard-Lebenszyklus-Methoden (Dev/Test/Prod), die Versionierung und simulierte Tests für die End-to-End-Orchestrierung umfassen.

Die Datenpipeline-Orchestrierung ist eine Lösung, mit der DataOps-Teams die Verwaltung und Steuerung von End-to-End-Datenpipelines zentralisieren können. Dabei integrieren Datenteams die Orchestrierungslösung in jedes Datentool, das sie entlang der Datenpipeline einsetzen. Daraufhin kann die Lösung zur Orchestrierung von Datenpipelines Aktionen des jeweiligen Datentools automatisieren, was dazu beiträgt dass die Daten jede Phase der gesamten Pipeline zuverlässig durchlaufen.
Zu den Vorteilen eines solchen Orchestrierungsansatzes gehören häufig Überwachungs- und Reportingfunktionen, proaktive Warnmeldungen, DataOps Enablement und die Übertragung von Daten in Echtzeit mit ereignisbasierten Systemauslösern.
Service-Orchestrierungs- und Automatisierungsplattformen (SOAP). Die von Gartner im April 2020 eingeführte Kategorie „SOAP“ hat sich aus den traditionellen Workload-Automatisierungslösungen entwickelt. Heute helfen SOAPs den I&O-Teams, Automation-as-a-Service für das Unternehmen bereitzustellen.
Eine der wichtigsten Lösungen, die in SOAPs integriert sind, ist die Datenpipeline-Orchestrierung. SOAPs sind dafür ideale Plattformen, da sie über einen grafischen Workflow-Designer verfügen, sich in Tools von Drittanbietern einbetten lassen und über integrierte Managed File Transfer-Funktionen verfügen.
Bekannt wurden SOAPs im Zuge der wachsenden Popularität der Cloud, die dazu führte, dass Unternehmen die Automatisierung sowohl in On-Prem- als auch in Cloud-Umgebungen orchestrieren mussten.
Fazit
Datenpipelines sind eine komplexe Angelegenheit; und es gibt keine Möglichkeit, diese Komplexität zu reduzieren, denn damit würde auch ihre Effektivität verloren gehen. Trotzdem ist die Orchestrierung und Automatisierung des Datenflusses durch eine Datenpipeline ein absolut machbares Unterfangen.
Mithilfe der oben aufgeführten Definitionen sind Sie schon ein gutes Stück näher dran, herauszufinden, wie Sie Ihre Datenpipeline-Strategie anpassen können. Dieser Artikel fasst zusammen, warum sich Unternehmen auf die Automatisierung der Datenpipeline konzentrieren. Wenn Sie sich weiter für das Thema interessieren, ist der Artikel ein hervorragender nächster Schritt.
Start Your Automation Initiative Now
Schedule a Live Demo with a Stonebranch Solution Expert




